Tra mode e censure, Google svela la storia delle parole
Mondo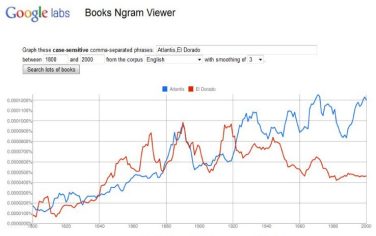
Il motore di ricerca con Books Ngram Viewer setaccia 5,2 milioni di libri e 500 miliardi di vocaboli. E svela la censura cinese di Piazza Tienanmen, ma anche la popolarità tra gli inglesi, dagli anni '80, della pizza. E così nasce la "Culturomics"
Guarda anche:
Sono 129.846.880 i libri del mondo. Parola di Google
Street art view: con Google scopri i graffiti del mondo
Google doodle: il logo giusto per ogni ricorrenza. GALLERY
Parole, parole, parole... Tutte le tag cloud di Sky.it
di Serenella Mattera
Jimmy Carter batte Marilyn Monroe e Mickey Mouse messi insieme. La pizza batte gli spaghetti, ma solo dagli anni ’80. La Francia batte la Germania, la Germania batte l’Italia (dagli inizi del ‘900), l’Italia batte (di misura) la Spagna. Comunismo batte fascismo, tranne che negli anni ‘40. Si potrebbe continuare all’infinito, nella speciale classifica delle parole. E scoprire, a pochi giorni dalla festa della donna, che il termine “women” (donne) negli ultimi cinque secoli solo per qualche anno, sul finire dei ’90, l’ha avuta vinta su “men” (uomini). O che nei testi di lingua tedesca degli anni ’30 e ’40 scompaiono quasi del tutto i nomi degli artisti messi al bando dal nazismo, come l’ebreo Marc Chagall o Pablo Picasso. E allora, quello che potrebbe a prima vista apparire un gioco, diventa strumento di studio a tutti gli effetti.
Lo speciale motore di ricerca, che porta il marchio Google, si chiama Books Ngram Viewer e consente di scoprire quante volte una parola è stata citata nei libri, in un lungo arco di tempo che va dal 1500 al 2008. Non in tutti i libri, naturalmente. Ma in una significativa parte di essi, dal momento che la ricerca viene svolta tra 5,2 milioni di volumi digitalizzati da Google Books (circa 500 miliardi di parole), ossia il 4% dell’intera produzione umana da quando è stata inventata la stampa.
Il meccanismo è semplice: si digita il termine, si sceglie un arco temporale e compare un diagramma che mostra il trend dell’uso di quel vocabolo. Sotto il diagramma, una serie di link rimandano direttamente ai testi che contengono la parola. Ma non solo. Basta inserire più di un sostantivo per avviare confronti e stilare classifiche: tra personaggi, luoghi, animali o anche cibi.
Unico neo dell’esperimento, dalla prospettiva del Bel paese, è la mancanza dell’italiano tra le sette lingue (inglese, tedesco, francese, spagnolo, cinese, russo, ebreo) nelle quali è possibile eseguire la ricerca. Anche se niente vieta di rintracciare la parola “Italia” nei testi in inglese e scoprire che il suo momento d’oro è stato tra il 1700 e il 1750. Mentre il termine “ciao” è di gran voga solo dagli anni Duemila.
Tutto nasce da un’idea del 2007 di un ricercatore di Harvard, Erez Lieberman Aiden, che propone a Google di mappare le parole utilizzate nei libri archiviati da Google Books, così come si fa per il genoma umano. Da lì a tre anni, a dicembre del 2010, sarebbe stata consacrata da un articolo sulla rivista Science la “Culturomics”, un metodo di ricerca che usa anche criteri quantitativi per studiare la cultura. E sarebbe stato battezzato come suo strumento principe il Books Ngram Viewer.
Gli studiosi finora hanno potuto evidenziare diversi trend e rintracciare migliaia di parole che non erano mai state registrate in nessun vocabolario inglese. Inoltre, hanno illustrato fenomeni come la quasi totale scomparsa di Piazza Tienanmen dalle pubblicazioni in cinese dopo il 1989 e la contemporanea “scoperta” di quel luogo di Pechino nei libri nelle altre lingue.
Ma le applicazioni del nuovo motore di ricerca possono essere le più varie. Come quella suggerita sul blog di Google Books in occasione dell’ultimo San Valentino: andare a caccia di mode in fatto di nomignoli romantici. Dal “my dear” usato da Rhett Butler per Rossella O’Hara, al “my sweet” con cui Romeo si rivolgeva a Giulietta. E magari i classici francesi “mon amour”, “ma belle”, “mon cher”, “mon amie”.
Sono 129.846.880 i libri del mondo. Parola di Google
Street art view: con Google scopri i graffiti del mondo
Google doodle: il logo giusto per ogni ricorrenza. GALLERY
Parole, parole, parole... Tutte le tag cloud di Sky.it
di Serenella Mattera
Jimmy Carter batte Marilyn Monroe e Mickey Mouse messi insieme. La pizza batte gli spaghetti, ma solo dagli anni ’80. La Francia batte la Germania, la Germania batte l’Italia (dagli inizi del ‘900), l’Italia batte (di misura) la Spagna. Comunismo batte fascismo, tranne che negli anni ‘40. Si potrebbe continuare all’infinito, nella speciale classifica delle parole. E scoprire, a pochi giorni dalla festa della donna, che il termine “women” (donne) negli ultimi cinque secoli solo per qualche anno, sul finire dei ’90, l’ha avuta vinta su “men” (uomini). O che nei testi di lingua tedesca degli anni ’30 e ’40 scompaiono quasi del tutto i nomi degli artisti messi al bando dal nazismo, come l’ebreo Marc Chagall o Pablo Picasso. E allora, quello che potrebbe a prima vista apparire un gioco, diventa strumento di studio a tutti gli effetti.
Lo speciale motore di ricerca, che porta il marchio Google, si chiama Books Ngram Viewer e consente di scoprire quante volte una parola è stata citata nei libri, in un lungo arco di tempo che va dal 1500 al 2008. Non in tutti i libri, naturalmente. Ma in una significativa parte di essi, dal momento che la ricerca viene svolta tra 5,2 milioni di volumi digitalizzati da Google Books (circa 500 miliardi di parole), ossia il 4% dell’intera produzione umana da quando è stata inventata la stampa.
Il meccanismo è semplice: si digita il termine, si sceglie un arco temporale e compare un diagramma che mostra il trend dell’uso di quel vocabolo. Sotto il diagramma, una serie di link rimandano direttamente ai testi che contengono la parola. Ma non solo. Basta inserire più di un sostantivo per avviare confronti e stilare classifiche: tra personaggi, luoghi, animali o anche cibi.
Unico neo dell’esperimento, dalla prospettiva del Bel paese, è la mancanza dell’italiano tra le sette lingue (inglese, tedesco, francese, spagnolo, cinese, russo, ebreo) nelle quali è possibile eseguire la ricerca. Anche se niente vieta di rintracciare la parola “Italia” nei testi in inglese e scoprire che il suo momento d’oro è stato tra il 1700 e il 1750. Mentre il termine “ciao” è di gran voga solo dagli anni Duemila.
Tutto nasce da un’idea del 2007 di un ricercatore di Harvard, Erez Lieberman Aiden, che propone a Google di mappare le parole utilizzate nei libri archiviati da Google Books, così come si fa per il genoma umano. Da lì a tre anni, a dicembre del 2010, sarebbe stata consacrata da un articolo sulla rivista Science la “Culturomics”, un metodo di ricerca che usa anche criteri quantitativi per studiare la cultura. E sarebbe stato battezzato come suo strumento principe il Books Ngram Viewer.
Gli studiosi finora hanno potuto evidenziare diversi trend e rintracciare migliaia di parole che non erano mai state registrate in nessun vocabolario inglese. Inoltre, hanno illustrato fenomeni come la quasi totale scomparsa di Piazza Tienanmen dalle pubblicazioni in cinese dopo il 1989 e la contemporanea “scoperta” di quel luogo di Pechino nei libri nelle altre lingue.
Ma le applicazioni del nuovo motore di ricerca possono essere le più varie. Come quella suggerita sul blog di Google Books in occasione dell’ultimo San Valentino: andare a caccia di mode in fatto di nomignoli romantici. Dal “my dear” usato da Rhett Butler per Rossella O’Hara, al “my sweet” con cui Romeo si rivolgeva a Giulietta. E magari i classici francesi “mon amour”, “ma belle”, “mon cher”, “mon amie”.
)
)
)
)
)